
 図1 学習データセット
openCVによる学習
traincascadeによりカスケード型AdaBoost識別器を作成した。
BTと検出位置の比較
検出した台風位置とBTの位置の比較を行う。
正検出‥BT位置から600km圏内の場合。
見逃し‥BTでは台風とされているものを検出しない場合。
空振り‥台風でないものを検出した場合、
または、台風を検出していても、600km圏外の場合。
3) 結果と考察
図1 学習データセット
openCVによる学習
traincascadeによりカスケード型AdaBoost識別器を作成した。
BTと検出位置の比較
検出した台風位置とBTの位置の比較を行う。
正検出‥BT位置から600km圏内の場合。
見逃し‥BTでは台風とされているものを検出しない場合。
空振り‥台風でないものを検出した場合、
または、台風を検出していても、600km圏外の場合。
3) 結果と考察
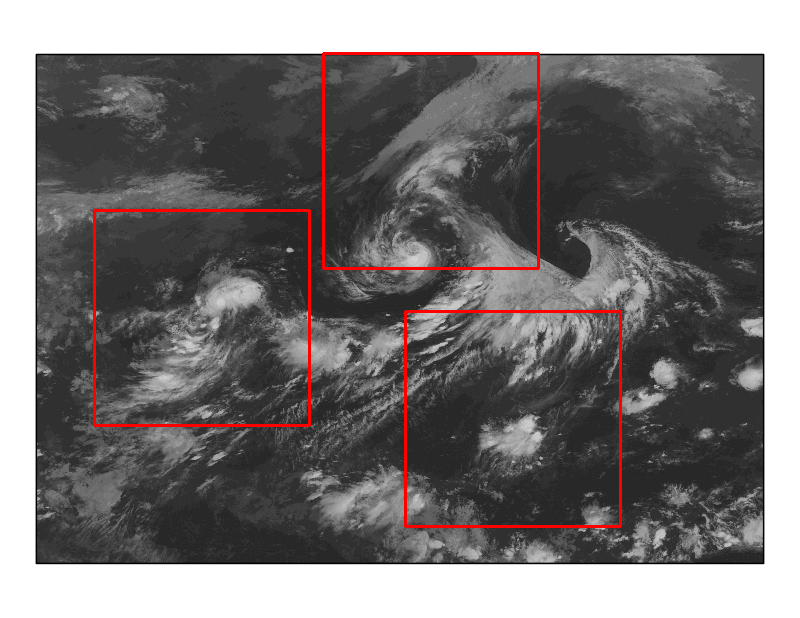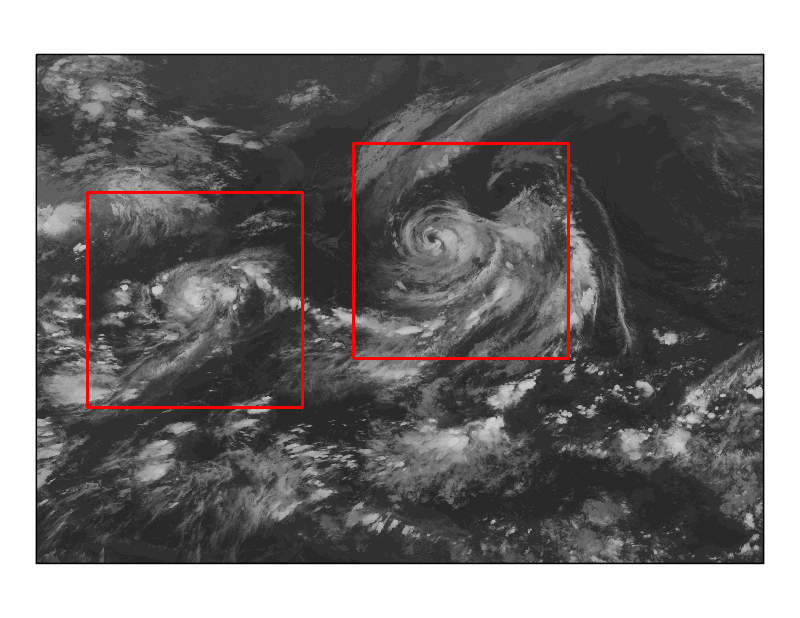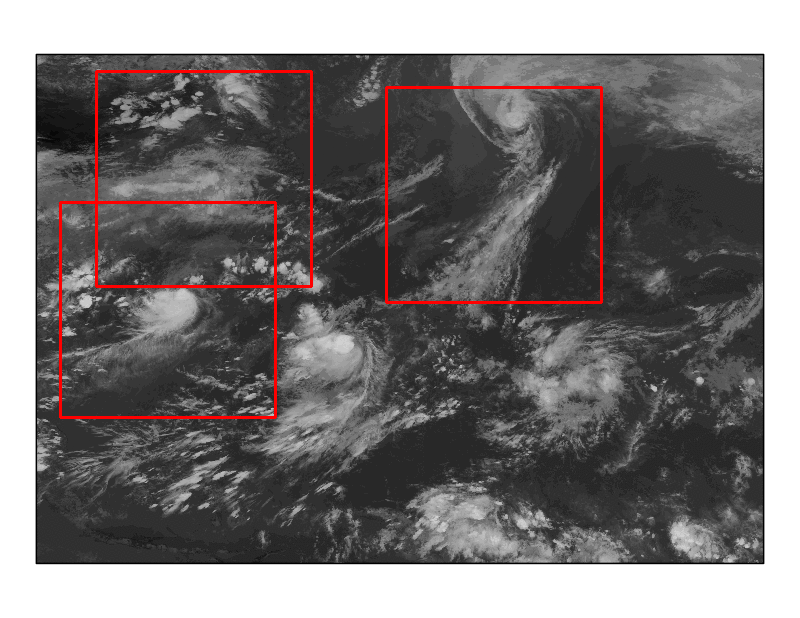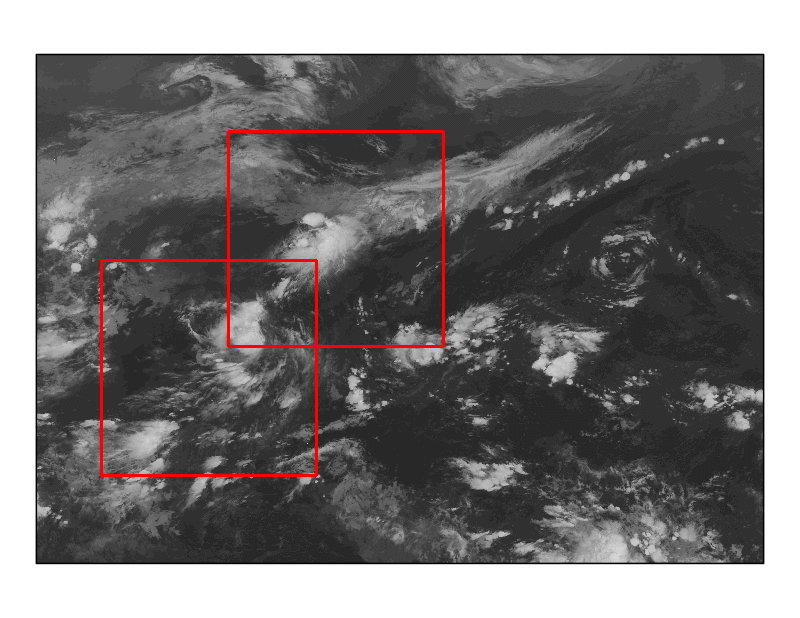 図2 検出の様子
3.1) モデル評価
図3は、本研究で作成したモデルの評価を表したものである。
水蒸気画像を学習データとしたモデルは全体的にグラフの左よりで、全てのモデルで検出率が低い事がわかった。
一方で、赤外画像を学習データとしたモデルは、パラメータによって検出率が約20 %の低い事例から、約90%の高い事例まで見られた。
最も評価が高いモデルとして、H20-S170(検出率が72.30%、適合率が25.79%)が挙げられ、
検出率が最も高いモデルは、H05-S150(検出率が91.25%、適合率が13.21%)となっていた。
図2 検出の様子
3.1) モデル評価
図3は、本研究で作成したモデルの評価を表したものである。
水蒸気画像を学習データとしたモデルは全体的にグラフの左よりで、全てのモデルで検出率が低い事がわかった。
一方で、赤外画像を学習データとしたモデルは、パラメータによって検出率が約20 %の低い事例から、約90%の高い事例まで見られた。
最も評価が高いモデルとして、H20-S170(検出率が72.30%、適合率が25.79%)が挙げられ、
検出率が最も高いモデルは、H05-S150(検出率が91.25%、適合率が13.21%)となっていた。
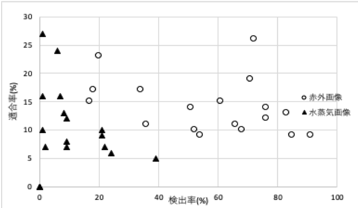 図3 モデル評価
3.2) 中心気圧におけるの検証
図4は、正検出時の中心気圧(hPa)と見逃し時の中心気圧(hPa)の分布を示した箱ひげ図である。
左図は分布が似ている事例(T1708)、右図は似ていない事例(T1714)である。
両事例とも、正検出時の中心気圧が、見逃し時の中心気圧よりも低くなっていた。
全台風事例で、同様の結果を得られた。
以上から、勢力の強い台風ほど検出しやすく、勢力の弱い台風を検出しにくいことがわかった。
図3 モデル評価
3.2) 中心気圧におけるの検証
図4は、正検出時の中心気圧(hPa)と見逃し時の中心気圧(hPa)の分布を示した箱ひげ図である。
左図は分布が似ている事例(T1708)、右図は似ていない事例(T1714)である。
両事例とも、正検出時の中心気圧が、見逃し時の中心気圧よりも低くなっていた。
全台風事例で、同様の結果を得られた。
以上から、勢力の強い台風ほど検出しやすく、勢力の弱い台風を検出しにくいことがわかった。
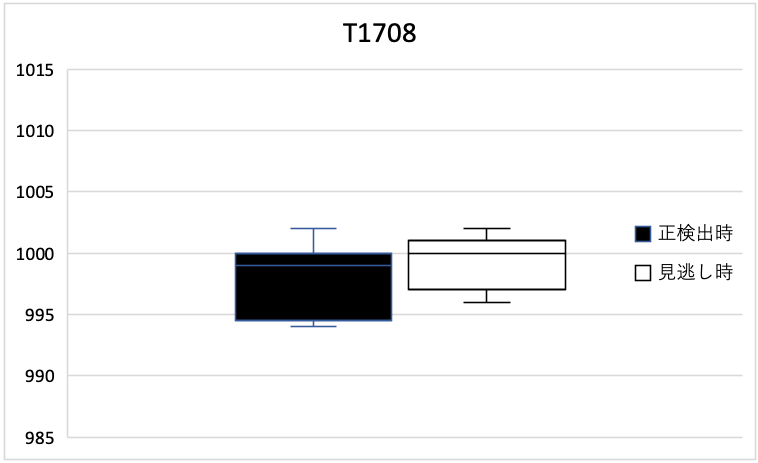
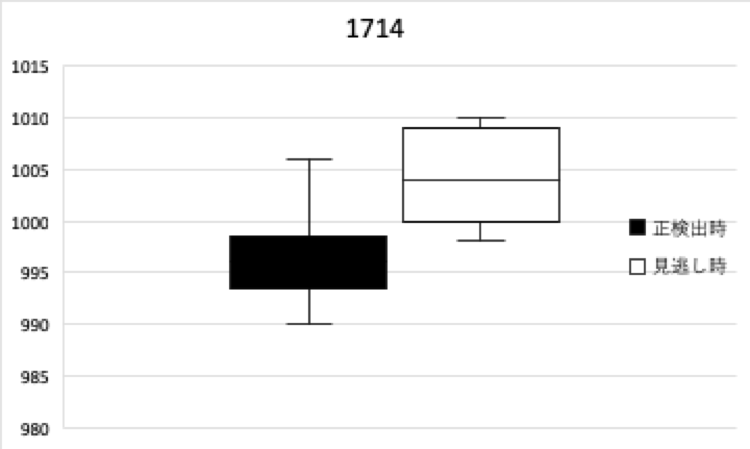 図4 H20-S170における台風事例別の正検出時の中心気圧(hPa)(黒)と見逃し時の中心気圧(hPa)(白)。
左図は分布が似ている事例(T1708)、右図は似ていない事例(T1714)。
4) まとめ
勢力の強い台風の検出が容易で、勢力の弱い台風や発生期、衰弱期など
中心気圧が高い時期の検出が困難であることがわかった。
今後は画像認識の観点から気象衛星雲画像の解析と台風の特徴パターンを解析をするなどで、検出できた台風は、なぜ検出ができたのか。検出できなかった台風は、なぜ検出ができなかったのかを明らかにしていきたい。
5) 謝辞
本研究を行うにあたり、JAMSTECの松岡大祐様、NOAA Earth System Research Laboratoryの吉田龍二様から多くのご指導をいただきました。
また、本研究で用いたひまわり8号のデータは千葉大から提供していただきました。
この場を借りて厚く御礼申し上げます。
図4 H20-S170における台風事例別の正検出時の中心気圧(hPa)(黒)と見逃し時の中心気圧(hPa)(白)。
左図は分布が似ている事例(T1708)、右図は似ていない事例(T1714)。
4) まとめ
勢力の強い台風の検出が容易で、勢力の弱い台風や発生期、衰弱期など
中心気圧が高い時期の検出が困難であることがわかった。
今後は画像認識の観点から気象衛星雲画像の解析と台風の特徴パターンを解析をするなどで、検出できた台風は、なぜ検出ができたのか。検出できなかった台風は、なぜ検出ができなかったのかを明らかにしていきたい。
5) 謝辞
本研究を行うにあたり、JAMSTECの松岡大祐様、NOAA Earth System Research Laboratoryの吉田龍二様から多くのご指導をいただきました。
また、本研究で用いたひまわり8号のデータは千葉大から提供していただきました。
この場を借りて厚く御礼申し上げます。
2019/03/20 金崎